

















A well-designed incident response (IR) plan is a powerful tool an organization can use to help protect its data, reputation, and operations. It provides a clear, documented process for preparing for, detecting, and recovering from cybersecurity incidents.
When done right, an IR plan helps you:
- Minimize downtime and business disruption.
- Protect sensitive information against loss or exposure.
- Reduce financial and legal risk by meeting regulatory requirements.
- Coordinate teams effectively under pressure.
- Capture lessons learned to strengthen defenses over time.
Whether you’re designing a plan for the first time or updating an existing one, knowing how to create an incident response plan ensures that your organization can act quickly and confidently when threats arise. To make implementation easier, you can also download a free incident response plan template to customize for your environment.
Comparing NIST and SANS incident response models
When designing an effective incident response strategy, choose a framework that provides both structure and flexibility.
Two of the most widely used options are the NIST Computer Security Incident Handling Guide SP 800-61 and the SANS Incident Response Framework.
Both outline clear, repeatable steps for handling security incidents, but they differ slightly in focus and level of granularity. Understanding how each framework approaches preparation, detection, containment, and recovery can help organizations select — or blend — the model that best supports their operational needs and regulatory obligations.
NIST Computer Security Incident Handling Guide SP 800-61
The NIST Computer Security Incident Handling Guide is a widely recognized framework, providing a structured lifecycle for preparing for, detecting, and responding to security incidents.
It breaks the incident response process into four key phases: Preparation, Detection and Analysis, Containment/Eradication/Recovery, and Post-Incident Activity. These phases give organizations a repeatable roadmap for handling threats and strengthening defenses over time.
- Preparation: Establish policies, train staff, and deploy tools before an incident occurs.
- Detection and Analysis: Identify events, confirm incidents, and evaluate their scope.
- Containment, Eradication, and Recovery: Limit damage, remove the threat, and restore systems securely.
- Post-Incident Activity: Document findings, improve processes, build playbooks, and share insights.
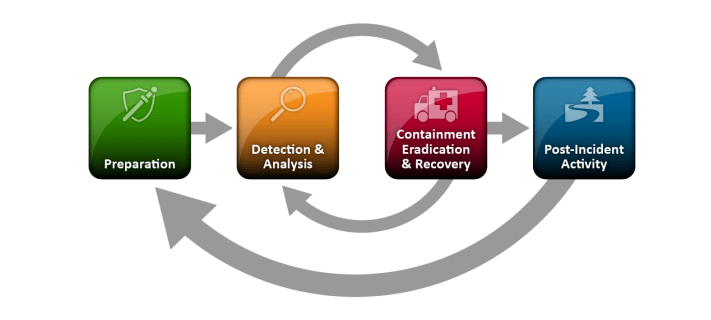
By following these four phases, organizations gain a clear and repeatable process for responding to cybersecurity incidents of any size. The NIST Computer Security Incident Handling Guide helps teams limit damage and recover quickly while also encouraging continuous improvement so future attacks can be detected and contained even faster.
SANS Incident Response Framework
Another framework for building an incident response plan is the SANS Incident Response Framework.
Known for its practical, operations-focused guidance, SANS lays out clear stages that security teams can follow during an incident, from preparation through post-event analysis.
By separating containment, eradication, and recovery into distinct steps, it provides greater tactical clarity, making it easier for organizations to assign ownership, measure progress, and keep response efforts organized.
These six steps include:
- Preparation: Establish policies, provide training, identify points of contact and key stakeholders for incidents, conduct tabletop exercises, and define the tools in use.
- Identification: Recognize and validate incidents.
- Containment: Short-term and long-term strategies to prevent spread.
- Eradication: Remove root causes and malicious artifacts.
- Recovery: Restore systems to normal operation and verify integrity.
- Lessons Learned: Conduct after-action reviews and process improvements.
You don’t need to choose one model exclusively. Many organizations borrow elements from both to suit their situation.
Steps to building an Incident Response Plan
Define the scope, purpose, and policies of your incident response plan
The first step in understanding how to create an incident response plan is defining its scope, purpose, and governing policies. Clarify why the plan exists, what systems, applications, and data it covers, and how it aligns with your organization’s overall security strategy. Include policies for reporting and escalating incidents, as well as procedures for obtaining executive approval when necessary.
A detailed incident response plan template can be invaluable here, providing ready-made sections for revision history, authority, definitions, and references. Customizing a template helps ensure your document captures all foundational elements — such as stakeholder contacts, severity matrices, and a clear incident-handling workflow — before you dive into the technical steps.
Establish an IR team and tabletop exercises
A solid plan is only as effective as the people who execute it. As you develop an incident response plan, focus on assembling a cross-functional team that includes technical responders, forensic specialists, legal counsel, communications staff, executive sponsors, and other key stakeholders.
Define their roles clearly and assign backup personnel for critical functions. In addition, there should be clear points of contact for external communication (e.g., contacting law enforcement).
You should also test the IR plan through tabletop exercises to ensure the organization can effectively handle emerging threats and that all stakeholders are aware of and can perform their responsibilities during an active incident.
Identify incident types and develop playbooks
Next, catalog the incident types most relevant to your environment, such as ransomware, phishing, insider threats, or cloud misconfigurations, and likely threats based on your industry. For example, healthcare providers face risks to medical devices, while dairy farms contend with entirely different threats.
For each one, develop a dedicated playbook detailing the steps for detection, containment, eradication, and recovery. Playbooks remove guesswork during a crisis, ensuring responders act consistently and according to policy.
Example IR Playbook: Phishing attack on front desk worker (PHI exposure)
- Detection & Reporting
- Front desk staff notices a suspicious email or unusual account activity and reports it to the security team.
- SOC analysts confirm phishing indicators (malicious link, credential harvesting site).
- Containment
- Immediately disable the compromised account and revoke active sessions.
- Isolate affected workstations from the network to prevent further data access.
- Eradication
- Remove malicious emails from mailboxes and block the sender’s domain.
- Scan the endpoint for malware and clean or reimage if needed.
- Recovery
- Reset the user’s credentials and enforce multi-factor authentication.
- Restore affected systems or files from clean backups if any were altered.
- Notification & Compliance
- Assess the scope of PHI exposure and notify compliance/legal teams.
- Report the breach to regulators (e.g., OCR under HIPAA) and inform impacted patients as required.
- Lessons Learned & Prevention
- Conduct a post-incident review to identify process gaps.
- Provide targeted phishing-awareness training for staff.
- Adjust email filtering and implement stricter access controls for PHI.
When mapping out how to create an incident response plan, incorporate these playbooks into your main document or attach them to your incident response plan template. Many security tools allow you to incorporate playbooks directly, which helps you automate your incident response.
Implement monitoring, detection, and recovery procedures
Effective monitoring and detection systems form the backbone of every successful IR strategy.
Deploy tools such as security information and event management (SIEM) platforms, endpoint detection and response (EDR), and log analysis solutions to identify suspicious behavior quickly.
Define clear escalation thresholds so that responders know when an event becomes an incident requiring immediate action.
Your plan should also describe containment, eradication, and recovery processes. For example, specify how to isolate infected endpoints, remove malicious code, and restore clean backups.
By outlining these steps directly, you give teams a clear, repeatable process for minimizing damage and restoring business operations.
Conduct post-incident reviews
The final step in creating an incident response plan is to ensure that your document remains a living resource.
After every incident, hold a formal review session to analyze root causes, evaluate the response, and identify areas for improvement. Document lessons learned, update policies, and adjust playbooks based on new threats or regulatory requirements.
Schedule periodic reviews to keep the plan relevant. A flexible incident response plan template simplifies these updates, making it easy to add new scenarios, revise contacts, and track version history without rebuilding your entire plan from scratch.
A strong incident response plan is more than a document — it’s a living framework that helps your organization act quickly, limit damage, and improve with every incident. By combining proven models like NIST or SANS with tailored playbooks, you can streamline preparation, detection, and recovery while keeping your team ready for emerging threats.
To maximize these efforts, consider pairing your plan with the best incident response tools that support rapid detection, orchestration, and post-incident analysis.
Free incident response templates
Two leading bodies in the cybersecurity industry provide detailed incident response templates:
- National Institute of Standards of Technology template
- SANS templates (categorized by specific areas of incident response)
While your business may want to copy such a template, they’re also good resources to inform your team’s individual plan, too. These are tools you can use to develop your own template, especially if your team hasn’t done this before and wants to pull from industry-leading expertise.