

















By Ted Dunning, MapR Technologies
Data has become too large to analyze with traditional tools, so companies are upping their security game by moving away from traditional approaches and instead using a combination of Apache Hadoop and advanced analytics to help predict, identify and deter security threats.
Hadoop can improve enterprise security in several different ways:
- Security Information and Event Management (SIEM). Hadoop can be used to analyze large amounts of real-time data from network and security devices
- Application Log Monitoring. Hadoop can improve application log data analysis
- Network Intrusion Detection. Network traffic can be analyzed in order to detect and report suspicious activity or intruders
- Fraud Detection. Hadoop can be used to perform anomaly detection on larger volumes and variety of data to detect and prevent fraudulent activities
- Risk Modeling. Risk assessment can be improved by building sophisticated machine learning models on Hadoop that can take into account thousands of indicators
Let’s look at a few examples of what Hadoop offers. But first, a quick word on anomaly detection. Hadoop can be used to build an anomaly detection system as a powerful defense against many kinds of risks.
If you don’t know exactly what the nature of the attack is, anomaly detection models can be useful in discovering suspicious events. Hadoop comes with libraries that allow you to build anomaly detection applications easily — although Hadoop can be used for a wide range of use cases that may not require the anomaly detection component.
Using Hadoop to Detect Phishing Attacks
Suppose you’re responsible for security at a bank’s website. You can perform anomaly detection using Hadoop in order to identify potentially fraudulent behavior. In a grossly simplified example, a machine-learning model can be used to quickly identify a phishing attack and flag it as suspicious.
An email is used to lure a customer to a fake website that looks just like his online bank. When the customer logs in, the fraud bot captures the information and uses it to log in to the real site to transfer out funds. The user is directed to the real login page, where they can log in, unaware that their account has been compromised.
In order to quickly detect this fraud attack, an anomaly detector compares the normal pattern found in Web logs to new and possibly anomalous behavior. A model of the data from the Web logs can tell the difference between the normal and anomalous patterns, as shown this figure from “Practical Machine Learning: A New Look at Anomaly Detection” by Ted Dunning and Ellen Friedman.
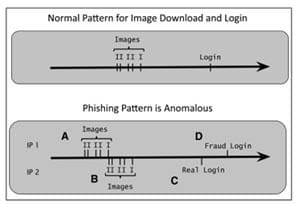 A page on the bank’s website can be designed to require information from image elements to be conveyed into the login request. This means the fraud-bot script is forced to use actual image elements from the real bank site on the decoy site; so there are two sets of image downloads and login events on the same timeline. The model can detect the problem and flag the account that has been hit by suspicious behavior. The bank can then put a hold on that customer’s account and notify him/her that there may have been an attack.
A page on the bank’s website can be designed to require information from image elements to be conveyed into the login request. This means the fraud-bot script is forced to use actual image elements from the real bank site on the decoy site; so there are two sets of image downloads and login events on the same timeline. The model can detect the problem and flag the account that has been hit by suspicious behavior. The bank can then put a hold on that customer’s account and notify him/her that there may have been an attack.
In order for this type of anomaly detection to work, a probabilistic model has to be built that can recognize a normal sequence of events. However, this can be harder than it sounds. The sequences that actually occur can be highly varied, and we end up with an unexpected result.
There could be many different situations where this result could occur, including these:
Quite a few Web browsers out there will only download a limited number of images at the same time, and often browsers will reuse the same TCP connection for many of the images, which could lead to no image overlap.
Load balancing or caching could also affect log data. These kinds of situations make it difficult to manually build an accurate description of what occurred.
To compensate, you would need to build a system that reads logs and automatically builds the model based on what actually happens, not necessarily based on what you would expect to be the case. By looking at hundreds or thousands of user session timelines, the actual patterns of log events can be used to build a model that is able to assign a “high probability” to sequences of events that are similar to those found in the logs. “Low probability” would be assigned to sequences that are dramatically different from those found in the logs.
Using Hadoop to Detect Card Fraud
Credit card fraud detection is another area that can benefit from anomaly detection. As a simple example, let’s say we have a data set that lists the amount you spend per credit card transaction. If a credit card company sees that suddenly you made a transaction that is much higher than your normal range of spending, that transaction would be considered a point anomaly. Typically, this kind of data includes more comprehensive records, such as type of purchases and time between transactions.
Since it can be difficult to detect fraud as the transaction is taking place, there are two different techniques that can be used to address this problem. “By-owner” is a technique in which you are profiled based on your credit card usage history. If you have a new transaction that doesn’t fit your profile, it can be flagged as an anomaly. “By-operation” is another type of approach that detects anomalies from transactions that take place at a particular geographic location. A transaction in San Francisco, followed 30 minutes later by a transaction in Florida, would be flagged as an anomaly.
Takeaway: New Approach Needed
As cyber security threats continue to evolve and grow more sophisticated, it’s imperative that you adopt a forward-looking approach to security. In order to be successful, you’ll need to move beyond traditional approaches and utilize both anomaly detection models and a real-time Hadoop platform in order to improve risk management and security.
Ted Dunning is chief application architect at MapR Technologies and committer and PMC member of the Apache Mahout, Apache ZooKeeper and Apache Drill projects. He has been active in mentoring new Apache projects and is currently serving as vice president of incubation for the Apache Software Foundation. He built fraud detection systems for ID Analytics (later purchased by LifeLock), and he has 24 patents issued to date and a dozen pending. He also bought the beer at the first Hadoop user group meeting.