Articles
Link to Top Cybersecurity Companies 
Top Cybersecurity Companies
The cybersecurity industry is constantly evolving. Learn about the top cybersecurity companies and what each does best.
Link to Threat Intelligence Platforms 
Threat Intelligence Platforms
Threat intelligence platforms help analyze and share cyber threat data. Discover top TIPs , their features, use cases, and comparisons.
Link to GRC Tools 
GRC Tools
Discover the top governance, risk and compliance (GRC) tools and software to help identify products that may suit your enterprise's needs.
Link to Network Access Control Solutions 
Network Access Control Solutions
Explore the top NAC solutions to ensure your network is only accessed by trusted users and avoid unwanted risks.
Link to Top NGFW 
Top NGFW
Explore the top next-generation firewall solutions. Assess features and pricing to discover the ideal NGFW solution for your needs.
Link to EDR Solutions 
EDR Solutions
EDR solutions ensure an organization's endpoints are running properly by monitoring and troubleshooting tech on the network. Compare the top tools now.
Articles
Link to What is Network Security? Definition, Threats & Protections 
What is Network Security? Definition, Threats & Protections
Learn about the fundamentals of network security and how to protect your organization from cyber threats.
Link to Network Protection: How to Secure a Network in 13 Steps 
Network Protection: How to Secure a Network in 13 Steps
Securing a network is a continuous process. Discover the process of securing networks from unwanted threats.
Link to Top 19 Network Security Threats + Defenses for Each 
Top 19 Network Security Threats + Defenses for Each
Discover the most common network security threats and how to protect your organization against them.
Link to 34 Most Common Types of Network Security Solutions 
34 Most Common Types of Network Security Solutions
Learn about the different types of network security and the different ways to protect your network.
Articles
View All
Hover to load posts
Articles
View All
Hover to load posts
Articles
View All
Hover to load posts
Articles
View All
Hover to load posts
Articles
View All
Hover to load posts
Articles
View All
Hover to load posts

- Best Products Link to Top Cybersecurity Companies Top Cybersecurity CompaniesThe cybersecurity industry is constantly evolving. Learn about the top cybersecurity companies and what each does best.Link to Threat Intelligence Platforms Threat Intelligence PlatformsThreat intelligence platforms help analyze and share cyber threat data. Discover top TIPs , their features, use cases, and comparisons.Link to GRC Tools GRC ToolsDiscover the top governance, risk and compliance (GRC) tools and software to help identify products that may suit your enterprise's needs.Link to Network Access Control Solutions Network Access Control SolutionsExplore the top NAC solutions to ensure your network is only accessed by trusted users and avoid unwanted risks.Link to Top NGFW Top NGFWExplore the top next-generation firewall solutions. Assess features and pricing to discover the ideal NGFW solution for your needs.Link to EDR Solutions EDR SolutionsEDR solutions ensure an organization's endpoints are running properly by monitoring and troubleshooting tech on the network. Compare the top tools now.
- Networks Link to What is Network Security? Definition, Threats & Protections What is Network Security? Definition, Threats & ProtectionsLearn about the fundamentals of network security and how to protect your organization from cyber threats.Link to Network Protection: How to Secure a Network in 13 Steps Network Protection: How to Secure a Network in 13 StepsSecuring a network is a continuous process. Discover the process of securing networks from unwanted threats.Link to Top 19 Network Security Threats + Defenses for Each Top 19 Network Security Threats + Defenses for EachDiscover the most common network security threats and how to protect your organization against them.Link to 34 Most Common Types of Network Security Solutions 34 Most Common Types of Network Security SolutionsLearn about the different types of network security and the different ways to protect your network.
-
Cloud -
Threats -
Trends -
Endpoint -
Applications -
-
Compliance


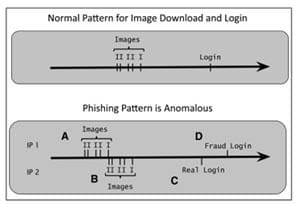 A page on the bank’s website can be designed to require information from image elements to be conveyed into the login request. This means the fraud-bot script is forced to use actual image elements from the real bank site on the decoy site; so there are two sets of image downloads and login events on the same timeline. The model can detect the problem and flag the account that has been hit by suspicious behavior. The bank can then put a hold on that customer’s account and notify him/her that there may have been an attack.
A page on the bank’s website can be designed to require information from image elements to be conveyed into the login request. This means the fraud-bot script is forced to use actual image elements from the real bank site on the decoy site; so there are two sets of image downloads and login events on the same timeline. The model can detect the problem and flag the account that has been hit by suspicious behavior. The bank can then put a hold on that customer’s account and notify him/her that there may have been an attack.






